Databases
Relational Database Service (RDS)
Это managed Database сервис для баз данных, что используют SQL в качестве языка запросов, то есть в реляционных баз данных — это тип базы данных, в которой данные организованы в строки и столбцы, которые вместе образуют таблицу, в которой точки данных связаны друг с другом. В таких базах данных используется Structured Query Language (SQL).
NoSQL databases используют JSON (JavaScript Object Notation), XML, YAML, или дв�оичные схемы, обеспечивающие неструктурированные данные. В таких схемах использется подход ключ-значение. Для подхода использования базы данных NoSQL - в AWS есть сервис DynamoDB - это serverless, NoSQL database service, в котором ты платишь только за использование конкретных запросов к ней, а в остальное время она скейлится в 0.
В RDS можно создать такие базы данных как: Postgres, MySQL, MariaDB, Microsoft SQL Server, IBM DB2, Aurora (AWS Proprietary database).
Преимущество использования RDS вместо самостоятельного развертывания на EC2 состоит в том, что нам не надо самостоятельно развертывать базу данных, ее обновлять, патчить, следить за ее состоянием, бекапить - это все будет производится на стороне AWS. Мы даже не сможем подключиться по SSH и нстансам баз данных.
Но есть такое понятие как RDS Custom, которое распространяется на Managed Oracle и Microsoft SQL Server Database. Это понятие подразумивает возможность настройки SSH соединения, конфигурировать настройки, устанавливать патчи - лучше все эти настройки выполнять при отключеном режиме RDS Automation и сделать снепшот.
! You can not create encrypted Read Replicas from an unencrypted RDS DB instance.
Storage Auto Scaling
Функция RDS, что позволяет увеличить место на базе данных динамично. То есть, если заканчивается свободное место на БД, то SAS автоматом накибывает больше памяти. Но для этого нужно установить Maximum Storage Threshold (максимальный лимит для пространства БД).
Также можно настроить автоматику на:
- Free storage is less than 10% of allocated storage;
- Low-storage lasts at 5 minutes;
- 6 hours have passed since last modification.
RDS Read Replicas vs Multi AZ
RDS Read Replicas обеспечивает повышенную производительность и надежность RDS, произв�одя масштабируемость за пределы ограничений емкости одного инстанса БД для рабочих нагрузок базы данных с большим объемом операций чтения.
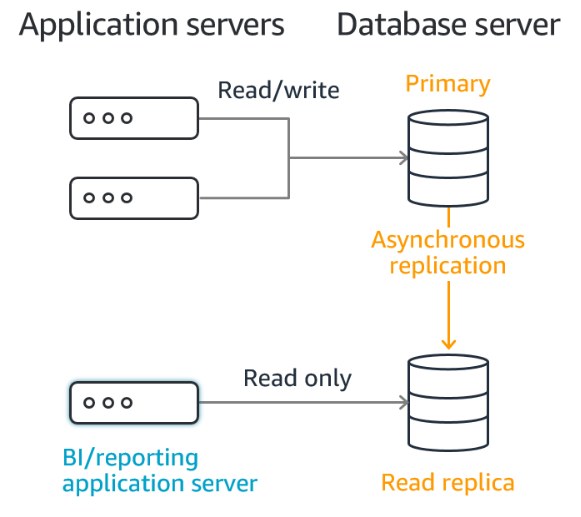
И мы можем создать до 15 таких READ реплик, внутри одной AZ, Cross AZ или Cross Region. Репликация является ASYNC (процесс работает независимо от других процессов, тогда как синхронная работа означает, что процесс запускается только в результате завершения или передачи какого-либо другого процесса), поэтому операции чтения в конечном итоге согласованы. Реплики могут быть повышены до собственных БД.
Приложения должны обновлять connection string, чтобы использовать READ реплики и использовать запросы под только под SELECT (INSERT, UPDATE, DELETE - недоступны в данном случае).
Use Case:
У нас есть приложение и база данных с нормальной нагрузкой и все ок, но тут к нам постучались бизнес аналитики и сказали, что теперь будут генерировать отчеты, используя базу данных. Для БД - это будет уже не ок нагрузка. Чтобы предотвратить проблемы с БД �можно использовать READ реплику для приложения по генерации отчетов.
Обычно в AWS ты платишь за отправку данных из одной AZ в другую, но есть исключения, которые, в основном, работают для AWS-manage сервисов. Для RDS не нужно платить за репликацию внутри региона. За Cross-Region придется платить.
Multi-AZ (Disaster Recovery)
Это когда мы реплицируем RDS Master DB инстанс синхронно (SYNC replication) в другую AZ от AZ мастер БД. Выглядит это так, что у мастер БД и резервной (standby) БД есть один DNS name и в случае проблем с мастер БД - произойдет автоматический фейловер к резервной БД. При создании Multi-AZ делается снепшот мастер БД и восстанавливается на резервной БД, после чего начинается процесс синхронизации с мастер БД.
Данный подход используется для фейловера мастер БД, не для скейлинга.
RDS Proxy
Эта фича позволяет объединять и совместно использовать соединения с базой данных, установленные с базой данных. RDS Proxy является serverless, умеет в autoscaling и HA (Multi-AZ)
Например, у нас есть VPC, где в приватной сабнете находится RDS DB Instance. В этой же сабнете находится и RDS Proxy. В этой же VPC находятся наши приложения-сервисы, которые обращаются к БД. RDS Proxy нужен, чтобы все существующие коннекшены с мсс'ов объединить в один. Это позволит снять с основного RDS DB Instance нагрузку по коннекшонам и снизить использование CPU, RAM. Также такой подход снизит время фейловера на 66%.
Amazon Aurora
СУБД от Amazon, не open-source решение. Имеет совместимость с Postgres и MySQL. Лучше всем оптимизирована под AWS, что дает ей 5х прирост в производительности по сравнению с MySQL и 3х с Postgres на RDS. Также есть плюшка 6 копиях наших данных среди 3-х AZ (4 копии из 6 для записи, 3 копии из 6 для чтения, self healing with peer-to-peer replication + Shared storage Volume). Быстрый фейловер в 30 секунд. Поддерживает Cross Region Replication. Имеет более обширный мониторинг из коробки.
Если мы хотим быть уверены, что у вас есть реплика нашей БД, доступной в другом регионе AWS, если в вашем основном регионе AWS произойдет авария, то стоит использовать Aurora Global Database. The maximum retention is only 35 days for Automated Backups. To store long-term backups for your Aurora database for disaster recovery and audit purposes - perform On Demand Backups.
Aurora DB Cluster
Есть мастер БД с DNS 'Writer Endpoint - Pointing to the master' (чтобы при фейловере приложения продолжали запись), что записывает в Shared storage Volu,e (Auto Expanding from 10G to 128TB). Есть коллекция рид реплик, что находятся под Auto Scaling с общим DNS 'Reader Endpoint - Connection Load Balancing', чтобы приложения не теряли связь с рид репликами.
Можно назначать Custom Endpoint на рид реплики, если тип реплик отличается.
ElastiCache
In-Memory Data Store, основная цель хранилища «ключ-значение» в памяти — обеспечить сверхбыстрый (с задержкой в доли миллисекунды) и недорогой доступ к копиям данных. В большинстве хранилищ данных есть области данных, к которым часто обращаются, но редко обновляют. Кроме того, запрос к базе данных всегда медленнее и дороже, чем поиск ключа в кэше пары ключ-значение. Выполнение некоторых запросов к базе данных особенно затратно. Примером являются запросы, включающие соединения нескольких таблиц или запросы с интенсивными вычислениями. Кэшируя такие результаты запроса, вы платите цену запроса только один раз. Затем вы сможете быстро получить данные несколько раз без необходимости повторного выполнения запроса.
В случае, как и с RDS, ElastiCache предлагает использовать In-Memory Data Store движки, а поддерживать их с точки зрения инфы AWS будет сам (OS maintenance, patching, optimizations, setup, configuration, monitoring, failure recovery and buckups).
Это выгдядит так, что приложение запрашивает ElastiCache: если все ок и кеш присутствует, то происходит
Cache hit, если кеша нет, тоCache missи запрос производится на RDS и сохраняется в ElastiCache. Но тут надо еще использоватьinvalidation strategy, чтобы точно знать, что используются самые актуальные данные. Или можно использовать ElastiCache для работы с пользовательскими сессиями в том плане, что приложения будут писать данные пользовательской сессии в ElastiCache. Если пользователь будет редиректиться на другое приложение, то данные из его сессии будут подтягиваться из ElastiCache.
Движками ElastiCache есть Redis или Memcached.
Redis
Remote Dictionary Server – хранилище данных «ключ – значение» в памяти, которое разработан как сервер и умеющий в HA со своими Read Replicas (которые можно скейлить), с возможностью backup and restore.
При создании Redis кластера, можно выбрать тип развертывания: Serverless или Design your own cache. При Serverless будет работать автоматика по анализу траффика приложения без создания сервера, что будет гораздо дороже, чем Design your own cache, где мы сами все настроить.
Только Redis поддерживает авторизацию по IAM. Или можно использовать Redis AUTH.
У Redis используется стратегия репликации - позволяет создать полный дубликат базы данных (вместо одного сервера их будет несколько). Репликация позволяет разгрузить основной сервер за счет переноса операций чтения на слейв.
Memcached
Спроектирован для простоты, а Redis предлагает богатый набор функций, которые делают его эффективным для широкого спектра случаев использования. Memcached без HA (репликации), без бекапов, неутойчивый к долговечности данных.
Supports SASL-based authentification (advanced).
У Memcached используется стратегия шардинга - техника масштабирования работы с данными, методом разделения (партиционирование) базы данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер. Этот процесс зависит от структуры Вашей базы данных и выполняется прямо в приложении в отличие от репликации. Крч, при этом подходе можно использовать одну БД и пытаться ее оптимизироваться для лучшей скорости работы и эффективности в целом.
List of Ports to be familiar with
Important ports:
- FTP: 21
- SSH: 22
- SFTP: 22 (same as SSH)
- HTTP: 80
- HTTPS: 443
vs RDS Databases ports:
- PostgreSQL: 5432
- MySQL: 3306
- Oracle RDS: 1521
- MSSQL Server: 1433
- MariaDB: 3306 (same as MySQL)
- Aurora: 5432 (if PostgreSQL compatible) or 3306 (if MySQL compatible)