Troubleshooting
OOMKilled
Container in pod has been OOMKilled 1 times in the last 120 minutes. По памяти планка идет 286 Мб, т.е. до лимита 364М, вроде запасик был. Скорее всего киллер его прибил, потому что на ноде было недостаточно ресурсов. У вас реквесты низковатые. Только реквест гарантируется. Лимит не гарантируется. Поду просто дают жрать выше реквеста, но ниж�е лимита только в случае, если на ноде есть свободные ресурсы.
NodeSystemSaturation
System load per core at node has been above 2 for the last 15 minutes, is currently at 4.78. This might indicate this instance resources saturation and can cause it becoming unresponsive. System saturated, load per core is very high. https://runbooks.prometheus-operator.dev/runbooks/node/nodesystemsaturation
Load Average - средняя нагрузка: https://phoenixnap.com/kb/linux-average-load
Это метрика, которая показывает количество задач, выполняемых в данный момент CPU, и задач, ожидающих в очереди.
В отличие от CPU Usage, которое измеряет производительность системы в определенный момент времени, Load Average показывает производительность за определенный период. Количество процессов, запущенных в системе, постоянно меняется, и Load Average отображает это изменение.
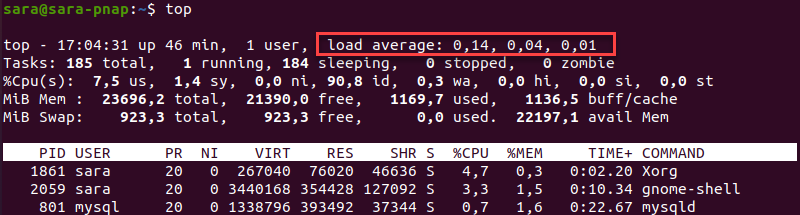 Вывод показывает, что система работает
Вывод показывает, что система работает 46 минут с момента последней загрузк�и, а количество активных пользователей равно 1. Средняя нагрузка на одного пользователя составляет:
0,14за последнюю1минуту.0,04за последние5минут.0,01за последние15минут.
Результаты рассчитываются путем деления количества запущенных и ожидающих процессов на количество доступных ядер CPU.
Terminated With Exit Code 1
https://komodor.com/learn/how-to-fix-container-terminated-with-exit-code-1/
K8S Pod Resources Optimization
В нас вимкнена фіча автоскейлингу кількості реплік, питання в контексті скейлингу ресурсів. Якщо аплікейшн досягає >=70% від request CPU, його буде піднято на іншому більш потужному інстансі з більшою доступною кілкістю CPU. А як щодо RAM? Що відбудеться з апкою якщо пікове навантаження перевищить встановлений лі�міт? Наприклад я встановив ліміт по RAM на 15% більше ніж рекомендоване значення пораховане по 95 персентилі. Скажімо це 194 Mb. Що відбудеться якщо аплікейшену буде потрібно 200 Мб ?
Майте на увазі що рантайм зазвичай бачить який limit виставили і відповідно підналаштовується під це, тобто якщо ви даєте занадто малий ліміт, то оптимізація програмного оточення може страждати (агресивне налаштування GC і менше кешування на рівні RAM), що може значно уповільнити роботу програми. Тому ліміт краще встановлювати від значень які показує програма при перфоманс тестах + якийсь відсоток (20-50%).
Також автоскейлінг краще ввімкнути якщо він адекватно підтримується мікросервісом:
{% if k8s.autoscaling.enabled == true %}
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: {{k8sSelector}}-scaling
namespace: {{k8sMSSNamespace}}
spec:
maxReplicas: {{k8s.autoscaling.maxNodes}}
minReplicas: {{k8s.autoscaling.minNodes}}
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: {{k8sSelector}}
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: {{k8s.autoscaling.averageCPUUtilizationPercentage}}
{% endif %}
З приводу де буде піднята наступна репліка при автоскейлі, в нас налаштований под анті афініті, тобто дві репліки одного MSS не повинні піднятися на одній k8s ноді, а далі все вирішує scheduler, по наявним ресурсам на рівні кластеру.
PVC
Handling PVC Deletion in StatefulSets: A Step-by-Step Recovery Guide